I was following this tutorial: Reconstructing density matrix, step by step but for a different system and I got the following error:
EDIT:: I got the same error when running the code of the tutorial using the same data as the one used in the tutorial.
TypeError Traceback (most recent call last)
<ipython-input-1-8ff604d7d30e> in <module>
74 ]
75
---> 76 nn_state.fit(
77 data=train_samples,
78 input_bases=train_bases,
~/.virtualenvs/qucumber/lib/python3.10/site-packages/qucumber-1.3.2-py3.10.egg/qucumber /nn_states/density_matrix.py in fit(self, data, epochs, pos_batch_size, neg_batch_size, k, lr, input_bases, progbar, starting_epoch, time, callbacks, optimizer, optimizer_args, scheduler, scheduler_args, **kwargs)
352 raise ValueError("input_bases must be provided to train a DensityMatrix!")
353 else:
--> 354 super().fit(
355 data=data,
356 epochs=epochs,
~/.virtualenvs/qucumber/lib/python3.10/site-packages/qucumber-1.3.2-py3.10.egg/qucumber/nn_states/neural_state.py in fit(self, data, epochs, pos_batch_size, neg_batch_size, k, lr, input_bases, progbar, starting_epoch, time, callbacks, optimizer, optimizer_args, scheduler, scheduler_args, **kwargs)
630 scheduler.step()
631
--> 632 callbacks.on_epoch_end(self, ep)
633 if self.stop_training: # check for stop_training signal
634 break
~/.virtualenvs/qucumber/lib/python3.10/site-packages/qucumber-1.3.2-py3.10.egg/qucumber/callbacks/callback_list.py in on_epoch_end(self, rbm, epoch)
69 def on_epoch_end(self, rbm, epoch):
70 for cb in self.callbacks:
---> 71 cb.on_epoch_end(rbm, epoch)
72
73 def on_batch_start(self, rbm, epoch, batch):
~/.virtualenvs/qucumber/lib/python3.10/site-packages/qucumber-1.3.2-py3.10.egg/qucumber/callbacks/metric_evaluator.py in on_epoch_end(self, nn_state, epoch)
131 metric_vals_for_epoch = {}
132 for metric_name, metric_fn in self.metrics.items():
--> 133 val = metric_fn(nn_state, **self.metric_kwargs)
134 metric_vals_for_epoch[metric_name] = val
135
~/.virtualenvs/qucumber/lib/python3.10/site-packages/qucumber-1.3.2-py3.10.egg/qucumber/utils/__init__.py in wrapped_f(*args, **kwargs)
70 def wrapped_f(*args, **kwargs):
71 kwargs = self.rename(f.__name__, kwargs)
---> 72 return f(*args, **kwargs)
73
74 return wrapped_f
~/.virtualenvs/qucumber/lib/python3.10/site-packages/qucumber-1.3.2-py3.10.egg/qucumber/utils/training_statistics.py in fidelity(nn_state, target, space, **kwargs)
70 # Instead of sqrt'ing then taking the trace, we compute the eigenvals,
71 # sqrt those, and then sum them up. This is a bit more efficient.
---> 72 eigvals = np.linalg.eigvals(prod).real # imaginary parts should be zero
73 eigvals = np.abs(eigvals)
74 trace = np.sum(np.sqrt(eigvals))
~/.virtualenvs/qucumber/lib/python3.10/site-packages/numpy/core/overrides.py in eigvals(*args, **kwargs)
~/.virtualenvs/qucumber/lib/python3.10/site-packages/numpy/linalg/linalg.py in eigvals(a)
1042 _assert_stacked_square(a)
1043 _assert_finite(a)
-> 1044 t, result_t = _commonType(a)
1045
1046 extobj = get_linalg_error_extobj(
~/.virtualenvs/qucumber/lib/python3.10/site-packages/numpy/linalg/linalg.py in _commonType(*arrays)
145 if rt is None:
146 # unsupported inexact scalar
--> 147 raise TypeError("array type %s is unsupported in linalg" %
148 (a.dtype.name,))
149 else:
TypeError: array type complex256 is unsupported in linalg
I don't believe the problem is with the Physics but with the matrix I am using, but I tried a torch.reshape(my_matrix, (-1,)) and I got the same error.
Details, if needed, are given below:
Samples of the matrices are:
GHZ_state_real.txt:

GHZ_state_imag.txt:
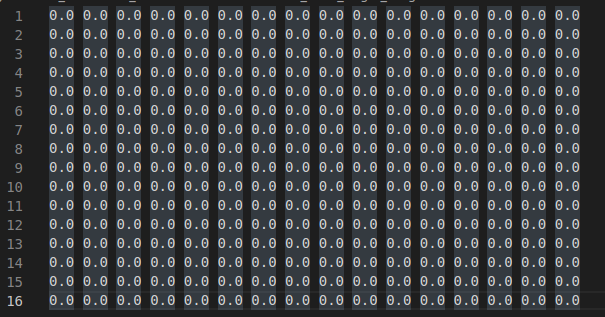
The first one is the real part of the system, and the second matrix is the imaginary part (just a bunch of zeros). Both are 16x16.
I loaded the data with:
import torch
from qucumber.nn_states import DensityMatrix
from qucumber.callbacks import MetricEvaluator
import qucumber.utils.unitaries as unitaries
import qucumber.utils.training_statistics as ts
import qucumber.utils.data as data
import qucumber
train_samples, true_matrix, train_bases, bases = data.load_data_DM(
train_path, matrix_path_real, matrix_path_imag, train_bases_path, bases_path
)
unitary_dict = unitaries.create_dict() #A dictionary with unitary matrix
nv = train_samples.shape[-1] # Number of visible layers for the RBM
nh = na = nv # Number of hidden and auxiliary layers
nn_state = DensityMatrix(
num_visible=nv, num_hidden=nh, num_aux=na, unitary_dict=unitary_dict, gpu=False
)
epochs = 500
pbs = 100 # pos_batch_size
nbs = pbs # neg_batch_size
lr = 10
k = 10
lr_drop_epoch = 125
lr_drop_factor = 0.5
def partition(nn_state, space, **kwargs):
return nn_state.rbm_am.partition(space)
period = 25
space = nn_state.generate_hilbert_space()
callbacks = [
MetricEvaluator(
period,
{
"Fidelity": ts.fidelity,
"KL": ts.KL,
"Partition Function": partition,
},
target=true_matrix,
bases=bases,
verbose=True,
space=space,
)
]
nn_state.fit(
data=train_samples,
input_bases=train_bases,
epochs=epochs,
pos_batch_size=pbs,
neg_batch_size=nbs,
lr=lr,
k=k,
bases=bases,
callbacks=callbacks,
time=True,
optimizer=torch.optim.Adadelta,
scheduler=torch.optim.lr_scheduler.StepLR,
scheduler_args={"step_size": lr_drop_epoch, "gamma": lr_drop_factor},
)
If you look at the link at the top you'll see that this is the same code that they used in the tutorial, but there the system is for a 2 qubit state, and here I am trying to reproduce for a 4 qubit state, thus my matrix is bigger.
The other data are:
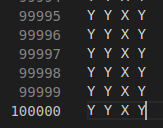
A 10k lines .txt file with 4 columns indicating the measurement bases for the system.

Which is just another 10k lines .txt file with measurement results.
And
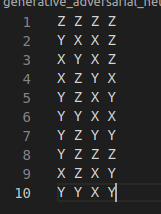
which is just a 10 line .txt indicating the unique measurement bases.
I don't know how to solve this problem and continue working. Is it a reshape problem or do I need to convert the complex256 to a complex128? According to this link numpy supported data types there is no complex256 data type supported in numpy, but my matrix are 16x16 and there is nothing I can do about it.
I a learning qucumber so I don't know if the piece of code which is producing this large dtype (complex256) is torch, numpy or qucumber. Probably it is because of the 16x16 matrix but how can I handle this?
Any help?
I was following this tutorial: Reconstructing density matrix, step by step but for a different system and I got the following error:
EDIT:: I got the same error when running the code of the tutorial using the same data as the one used in the tutorial.
I don't believe the problem is with the Physics but with the matrix I am using, but I tried a
torch.reshape(my_matrix, (-1,))and I got the same error.Details, if needed, are given below:
Samples of the matrices are:
GHZ_state_real.txt:GHZ_state_imag.txt:The first one is the real part of the system, and the second matrix is the imaginary part (just a bunch of zeros). Both are 16x16.
I loaded the data with:
If you look at the link at the top you'll see that this is the same code that they used in the tutorial, but there the system is for a 2 qubit state, and here I am trying to reproduce for a 4 qubit state, thus my matrix is bigger.
The other data are:
A 10k lines .txt file with 4 columns indicating the measurement bases for the system.
Which is just another 10k lines .txt file with measurement results.
And
which is just a 10 line .txt indicating the unique measurement bases.
I don't know how to solve this problem and continue working. Is it a reshape problem or do I need to convert the
complex256to acomplex128? According to this link numpy supported data types there is nocomplex256data type supported in numpy, but my matrix are 16x16 and there is nothing I can do about it.I a learning qucumber so I don't know if the piece of code which is producing this large dtype (complex256) is
torch,numpyorqucumber. Probably it is because of the 16x16 matrix but how can I handle this?Any help?